kube-prometheus-stackでメトリクスを可視化する
はじめに
自宅クラスタのリソース状況を把握するために、PrometheusとGrafanaのダッシュボードを整備しました。
本記事では、構築手順をメモとして残します。
- kube-prometheus-stack (Helm)
- ArgoCD でデプロイ
- Grafana で可視化
設定
Prometheus を Helm で定義する
Prometheusコミュニティが提供するkube-prometheus-stackは、Prometheus本体に加えてGrafanaやnode-exporter、kube-state-metricsなど監視に必要なコンポーネントを一式含んでいます。 私のクラスタでは既にGrafanaが稼働しており、必要なメトリクスも最小限で足りると判断したため、values.yamlで有効化するコンポーネントを絞り込みました。
ArgoCDでデプロイする
この設定でArgoCDにデプロイしてもらいました。
ArgoCDはHelmの場合、helm dependency build相当の処理を自動で実行してくれるので、Charts.yamlに依存関係を記載するだけで機能します。
また、ServerSideApply=trueにしないと下記エラーが発生するので注意してください(詳細は後述します)。
OperationCompleted Sync operation to 0175b2d9e28c3a09c825d351de3aa4947b163d02 failed: one or more synchronization tasks completed unsuccessfully, reason: CustomResourceDefinition.apiextensions.k8s.io "prometheusagents.monitoring.coreos.com" is invalid: metadata.annotations: Too long: may not be more than 262144 bytes,CustomResourceDefinition.apiextensions.k8s.io "prometheuses.monitoring.coreos.com" is invalid: metadata.annotations: Too long: may not be more than 262144 bytes,CustomResourceDefinition.apiextensions.k8s.io "scrapeconfigs.monitoring.coreos.com" is invalid: metadata.annotations: Too long: may not be more than 262144 bytes,CustomResourceDefinition.apiextensions.k8s.io "thanosrulers.monitoring.coreos.com" is invalid: metadata.annotations: Too long: may not be more than 262144 bytes,resource mapping not found for name: "home-k8s-metrics-kube-prom-alertmanager" namespace: "metrics" from "/dev/shm/2276355412": no matches for kind "Alertmanager" in version "monitoring.coreos.com/v1" ensure CRDs are installed first,resource mapping not found for name: "home-k8s-metrics-kube-prom-prometheus" namespace: "metrics" from "/dev/shm/2271548998": no matches for kind "Prometheus" in version "monitoring.coreos.com/v1" ensure CRDs are installed first,CustomResourceDefinition.apiextensions.k8s.io "alertmanagerconfigs.monitoring.coreos.com" is invalid: metadata.annotations: Too long: may not be more than 262144 bytes,CustomResourceDefinition.apiextensions.k8s.io "alertmanagers.monitoring.coreos.com" is invalid: metadata.annotations: Too long: may not be more than 262144 bytes (retried 5 times).Grafanaで可視化する
serviceリソースの情報を基にすると、URLはhttp://home-k8s-metrics-kube-prom-prometheus.metrics.svc:9090になるので、これをGrafanaのデータソースとして追加します。
$ kubectl get svc -A | grep prometheus
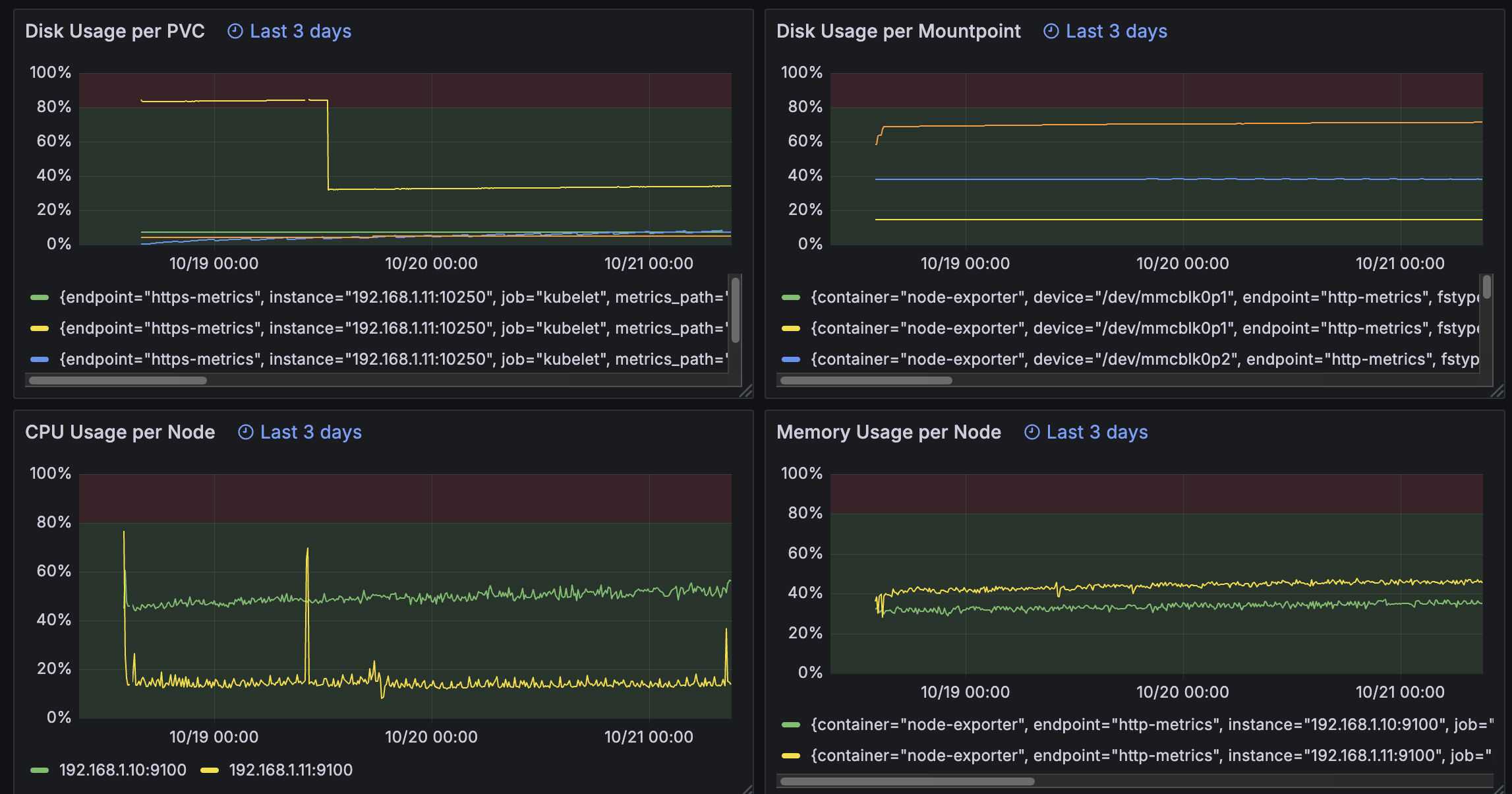
metrics home-k8s-metrics-kube-prom-prometheus ClusterIP 10.99.57.248 <none> 9090/TCP,8080/TCP 16h Grafana上では下記クエリで各種リソースの使用率を可視化しています。
Node毎のCPU使用率
100 * (1 - avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[1m])))
Node毎のメモリ使用率
100 * (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes))MountPoint毎のストレージ使用率
100 * (1 - (
node_filesystem_avail_bytes{fstype!~"tmpfs|overlay|squashfs",mountpoint!~"/(run|sys|proc|dev)($|/)"}
/
node_filesystem_size_bytes{fstype!~"tmpfs|overlay|squashfs",mountpoint!~"/(run|sys|proc|dev)($|/)"}
))
PVCの使用率
100 * kubelet_volume_stats_used_bytes
/ kubelet_volume_stats_capacity_bytesServerSideApplyについて
デフォルトではClientSideApplyが利用されます。kubectl apply を実行すると、マニフェスト全体が metadata.annotations["kubectl.kubernetes.io/last-applied-configuration"] に保存されます。
そして、次回実行時にマニフェスト・現状のリソースの状態・last-applied-configurationを比較(3-wayマージ)することで、リソースの作成・追加・削除の判断をする仕組みです。
ただし、これには問題があります。Applyの実行主体が複数ある際にリソースを上書きしてしまうことです。これを解決するためにServerSideApplyが導入されました。
ServerSideApplyでは各フィールドに所有権(Field Manager)が記録されます。所有権を持つタイミングはリソースの作成時や、既存リソースに対してApplyを行いフィールドの内容を宣言した際です。 所有権を持つものだけがそのフィールドを変更できるようになり、他の実行主体と衝突した場合はコンフリクトとして検出されます。
今回起こった問題は、ArgoCDがClientSideApply時にlast-applied-configurationを指定したものの、約256KBの上限を超えてしまったために適用できなかったことです。 マニフェストにServerSideApply=trueを指定し、ServerSideApplyを利用するようにして解決しています。
この問題は、一般的なKindを使う限りでは発生しにくいものの、CRDが使われるケースが増えている近年は発生することが多いようです。